
Agent 架构 从 Prompt 到 Context
本文不适合初学大模型的读者阅读,曾为字节排行榜榜首的位置,有一定阅读价值故转载
转载自https://blog.zippland.com/article/2259db82-fa86-8039-b227-d6098faedd22
本文是一篇对于大模型AI智能体(Agent)两个相关但层次不同的概念:“Prompt Engineering”(提示工程) 和 “Context Engineering”(上下文工程)的探讨。
背景
在观察去年以来对于 “Prompt Engineering” 的解构时,我们可以观察到一个微妙但重要的分歧。
一方面
专注于构建可扩展系统的前沿实践者们(如 Andrej Karpathy 等),积极倡导用 “Context Engineering” 来描述工作,认为 “Prompt Engineering” 这个词不足以涵盖复杂性,甚至戏称它只是
“Coming up with a laughably pretentious name for typing in the chat box(给在聊天框里打字起的一个可笑的自命不凡的名字)”。
因为他们构建 Agent 系统的核心挑战并非仅仅是 Prompt,而是设计整个数据流,以动态生成最终提示的架构。另一方面
近年来学术和正式文献则倾向用 “Prompt Engineering” 作为一个广义的 umbrella term(伞形术语),其定义包括了 Supporting content 或 Context,把所有在 不改变模型权重 的前提下操纵模型输入的技术归为同一类型。
术语分歧的意义
术语上的分歧可以反映该领域的成熟过程:随着 AI 应用从简单的单次交互发展到复杂的、有状态的智能体系统,优化静态指令已经无法满足需求。
因此,“Context Engineering” 的出现,是为了区分两种不同层次的活动:
- 编写指令的 skill
- 构建自动化系统以为该指令提供成功所需信息的科学
(本报告明确,尽管在学术上 Prompt Engineering 可能涵盖上下文,但在工程实践中,Context Engineering 是专注于如何动态构建和管理上下文的专门学科)
一、重新定义 Agent 数据流:Context is All You Need
本部分旨在建立 Prompt Engineering 与 Context Engineering 的基础概念,清晰地界定二者之间的区别与联系。
从前者到后者的转变,代表了人工智能应用开发领域的一次关键演进:
从业界最初关注的 战术性指令构建,转向由 可扩展、高可靠性系统需求驱动的战略性架构设计。
1.1 Prompt Engineering - the Art of Instructions
Prompt Engineering 是与大型语言模型(LLM)交互的基础,其核心在于 精心设计输入内容,以引导模型生成期望的输出。
这一实践为理解 Context Engineering 的必要性提供了基准。
定义
一个提示(Prompt)远不止一个简单的问题,它是一个 结构化的输入,可包含多个组成部分:
指令(Instructions)
对模型的核心任务指令,明确告知模型需要执行什么操作。主要内容/输入数据(Primary Content / Input Data)
模型需要处理的文本或数据,是分析、转换或生成任务的对象。示例(Examples / Shots)
演示期望的输入-输出行为,为模型提供“上下文学习”(In-Context Learning)的基础。线索 / 输出指示器(Cues / Output Indicators)
启动模型输出的引导性词语,或对输出格式(如 JSON、Markdown)的明确要求。支持性内容(Supporting Content / Context)
为模型提供的额外背景信息,帮助其更好地理解任务情境。
正是这一组件,构成了 Context Engineering 发展的概念萌芽。
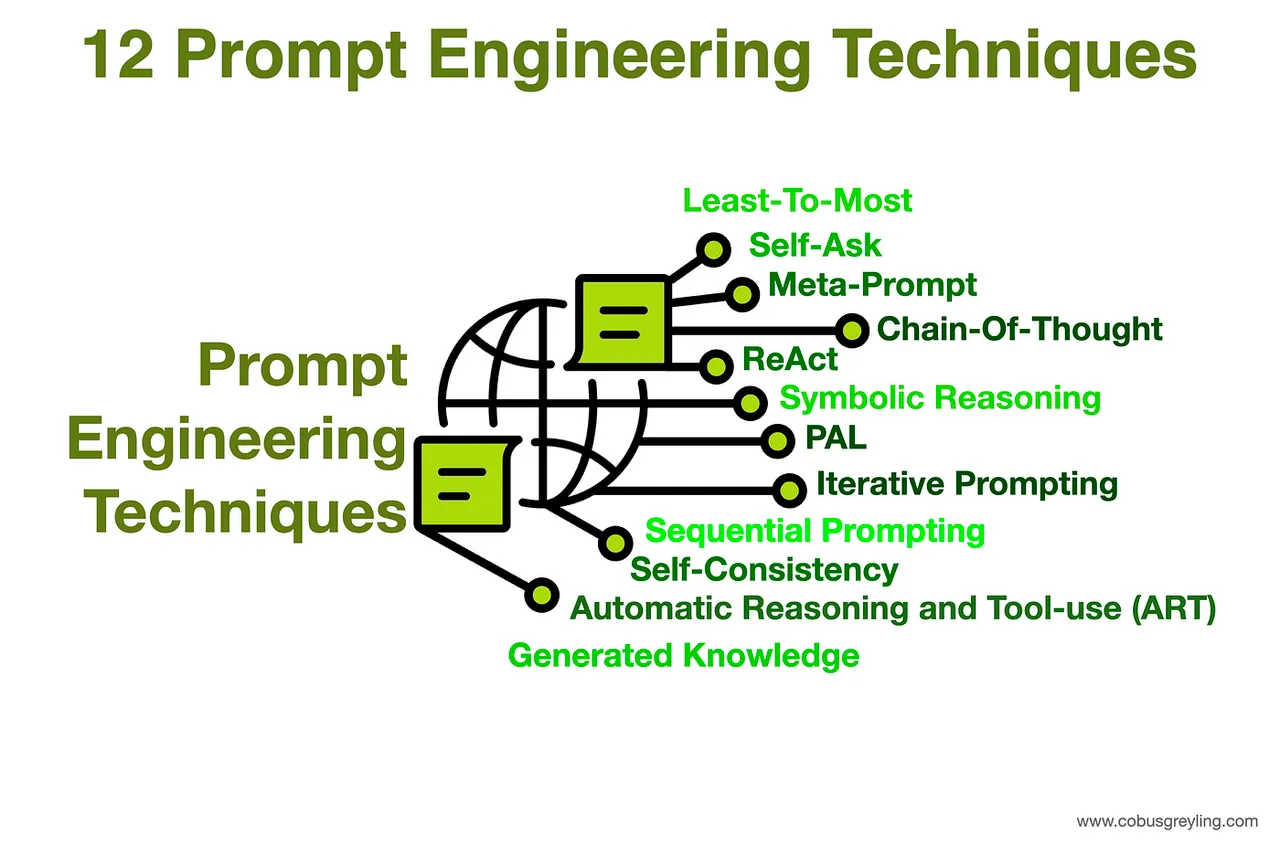
Prompt Engineering 的核心技术
Prompt Engineer 使用一系列技术来优化模型输出,这些技术可按复杂性进行分类:
零样本提示(Zero-Shot Prompting)
在不提供任何示例的情况下直接向模型下达任务,完全依赖其在预训练阶段获得的知识和推理能力。少样本提示(Few-Shot Prompting)
在提示中提供少量(通常为 1 到 5 个)高质量的示例,以引导模型的行为。对于复杂任务,这种“上下文学习”方法被证明极为有效。思维链提示(Chain-of-Thought Prompting, CoT)
引导模型将复杂问题分解为一系列中间推理步骤,显著增强了其在逻辑、数学和推理任务上的表现。高级推理技术
在 CoT 的基础上,研究人员还开发了更为复杂的变体,如:- 思维树(Tree-of-Thought)
- 苏格拉底式提示(Maieutic Prompting)
- 由简到繁提示(Least-to-Most Prompting)
以探索更多样化的解决方案路径。
以提示为中心的方法的局限性
尽管 Prompt Engineering 至关重要,但对于构建稳健、可用于生产环境的系统而言,它存在固有的局限性:
脆弱性 & 不可复现性
提示中微小的措辞变化可能导致输出结果的巨大差异,使得这一过程更像是一种依赖反复试错的“艺术”,而非可复现的“科学”。扩展性差
手动、迭代地优化提示的过程,在面对大量用户、多样化用例和不断出现的边缘情况时,难以有效扩展。用户负担
这种方法将精心构建一套详尽指令的负担完全压在了用户身上,对于需要自主运行、或处理高并发请求的系统而言是不切实际的。无状态性
Prompt Engineering 本质上是为单轮、“一次性”的交互而设计的,难以处理需要记忆和状态管理的长对话或多步骤任务。
1.2 Context Engineering 兴起:范式的转移
Context Engineering 并非要取代 Prompt Engineering,而是一个更高阶、更侧重于系统设计的必要学科。
定义 Context Engineering
Context Engineering 是一门设计、构建并优化动态自动化系统的学科,
旨在为大型语言模型在 正确的时间、以正确的格式,提供正确的信息和工具,
从而可靠、可扩展地完成复杂任务。
- Prompt 告诉模型 如何思考
- Context 则赋予模型 完成工作所需的知识和工具
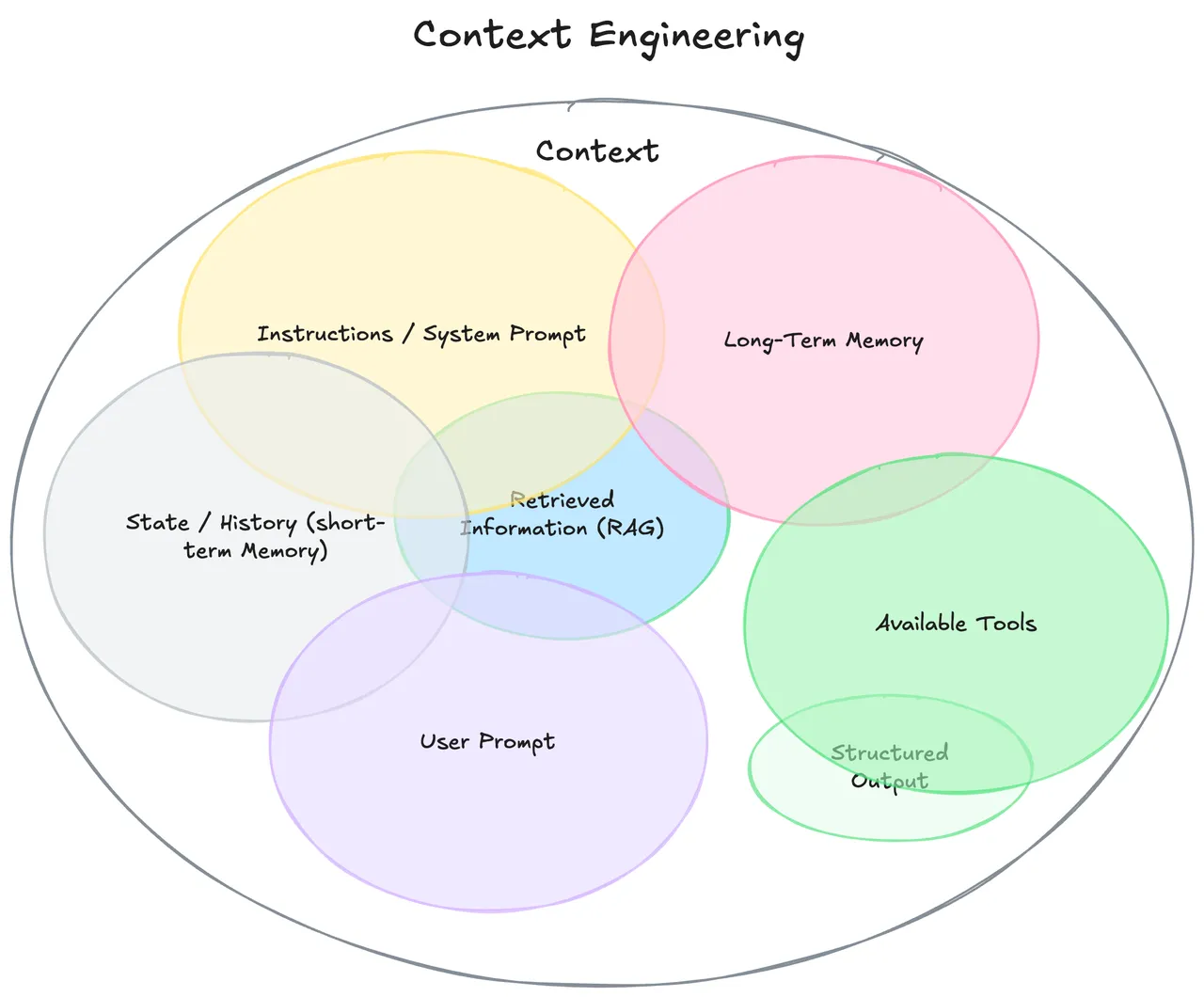
“Context”的范畴
“Context”的定义已远超用户单次的即时提示,它涵盖了 LLM 在做出响应前所能看到的 完整信息生态系统:
- 系统级指令和角色设定
- 对话历史(短期记忆)
- 持久化的用户偏好和事实(长期记忆)
- 动态检索的外部数据(例如来自 RAG)
- 可用的工具(API、函数)及其定义
- 期望的输出格式(例如 JSON Schema)
1.3 对比分析:Prompt Engineering vs Context Engineering
关系
- Prompt Engineering 是 Context Engineering 的子集
- Context Engineering 决定 用什么内容填充 Context Window
- Prompt Engineering 负责优化 窗口内的具体指令
对比表
| 比较维度 | Prompt Engineering | Context Engineering |
|---|---|---|
| 主要目标 | 获取特定的、一次性的响应 | 确保系统在不同会话和用户间表现一致、可靠 |
| 核心动作 | 创意写作、措辞优化(wordsmithing) | 系统设计、LLM 应用软件架构 |
| 范围 | 单个输入-输出对 | 整个信息流,包括记忆、工具、历史记录 |
| 模式 | 制作清晰的指令 | 设计模型的完整 思考流程 |
| 扩展性 | 脆弱,难以扩展到多用户和多场景 | 从设计之初就为规模化和可重用性而构建 |
| 所需工具 | 文本编辑器、聊天机器人界面 | RAG 系统、向量数据库、API 链、记忆模块等 |
| 调试方法 | 重写措辞、猜测模型意图 | 检查完整的 Context Window、数据流、Token 使用情况 |
二、Context Engineering 的基石:RAG(Retrieval-Augmented Generation)
2.1 RAG 的意义
RAG 不仅是一种技术,更是现代 Context Engineering 的基础架构。
它解决了标准 LLM 在企业应用中的核心弱点:
- 知识冻结:LLM 的知识停留在训练数据时间点;RAG 注入实时信息
- 缺乏专有知识:LLM 无法访问内部私有数据;RAG 可接入知识库
- 幻觉(Hallucination):RAG 让输出锚定在可验证证据上,提升可信度
2.2 RAG 工作流
索引(离线阶段)
- 加载文档 → 分块 → 向量化(Embedding) → 存入向量数据库
推理(在线阶段)
- 检索:用户查询向量化,与向量库搜索最相关文档
- 增强:将检索结果 + 用户查询 + 系统指令合并,构建增强提示
- 生成:输入 LLM,产出基于证据的回答
2.3 RAG 架构分类
- Naive RAG:最基础的问答场景,局限较多
- Advanced RAG:
- 检索前处理:更复杂的分块、查询优化(如 StepBack-prompting)
- 检索后处理:Re-ranking、上下文压缩
- Modular RAG:组件模块化(搜索、记忆、路由等)
- 带记忆 RAG
- 分支/路由 RAG
- **Corrective RAG (CRAG)**:加入评估器,自我修正
- Self-RAG:模型自主判断何时触发检索
- Agentic RAG:智能体循环中的 RAG,最先进形态
Context Stack:新兴抽象层
RAG 系统包含:数据摄入 → 分块 → 嵌入 → 向量数据库 → Re-ranking → 压缩 → LLM
这一流程形成了 Context Stack —— AI Agent 架构的系统层次。
- Database Layer:Pinecone、Weaviate、Milvus
- Application Orchestration Layer:LangChain、LlamaIndex
- **Re-ranking as a Service (RaaS)**:Cohere、Jina AI
向量数据库选型对比
| 数据库 | 关键差异点 | 理想用例 | 可扩展性 | 部署模型 | 索引算法 |
|---|---|---|---|---|---|
| Pinecone | 全托管、Serverless、低延迟 | 零运维、实时应用 | 高 | 托管云服务 | HNSW(默认) |
| Weaviate | 混合搜索、多模态支持 | 图文数据、复杂应用 | 高 | 开源/托管 | HNSW |
| Milvus | 大规模、高吞吐量、多算法 | 海量向量数据 | 极高 | 开源/托管 | HNSW, IVF, DiskANN |
| Qdrant | 高级过滤、内存效率 | 复杂元数据过滤 | 中-高 | 开源/托管 | HNSW |
三、Context 工程化:什么内容应进入上下文?
3.1 从原始数据到分块
- 朴素分块:固定大小,常切断语义
- 递归字符分割:按段落 → 句子 → 单词分层
- 文档特定分块:按 Markdown 标题、函数、合同条款
- 语言学分块:基于句法边界(NLTK、spaCy)
- 语义分块:基于嵌入检测语义变化点(性能最佳)
- 智能体分块:让 LLM 代理决定分块方式
3.1.2 重排序(Re-ranking)
- 两阶段检索:
- 召回(快速、粗粒度)
- 精排(交叉编码器,细粒度)
- 实际影响:显著提升上下文质量,减少幻觉(尤其在金融/法律等领域必需)
3.2 核心挑战:Lost in the Middle
Lost in the Middle (2023) 揭示了 LLM 的长上下文局限性:
- U 型性能曲线:开头和结尾信息易利用,中间信息常被忽略
- 实验结果:简单增加上下文长度无益,反而掩盖关键信息
- 本质问题:模型能编码信息,但未能有效利用
关键矛盾
- 提供丰富上下文 必要
- 但上下文窗口有限 + 认知偏差 → 性能下降
核心优化目标
在固定 Token 预算下:
- 最大化“信号”(相关信息)
- 最小化“噪声”(冗余或干扰)
这推动了语义分块、重排序、压缩、摘要、智能体隔离等技术的发展。
因此,Context Engineering 不仅是“提供上下文”,更是“如何策划上下文”。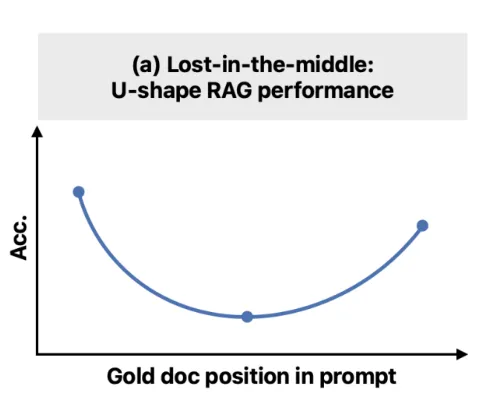
3.3 优化上下文窗口:压缩与摘要
上下文压缩的目标:
缩短检索到的文档列表和/或精简单个文档的内容,只将最相关的信息传递给 LLM。
这样能有效降低 API 调用成本、减少延迟,并缓解 Lost in the Middle 的问题。
压缩方法
过滤式压缩(Document-level Filtering)
- LLMChainFilter:利用 LLM 对每个文档的相关性做出“是/否”判断
- EmbeddingsFilter:计算文档嵌入与查询嵌入的余弦相似度,快速过滤低相关文档
内容提取式压缩(Content-level Extraction)
- LLMChainExtractor:遍历文档,用 LLM 提取仅与查询相关的句子或陈述
Top-N 替代压缩
- 通过 LLMListwiseRerank 等技术对检索到的文档进行重排序,仅保留排名最高的 N 个
作为压缩策略的摘要
- 对非常长的文档或冗长对话历史,用 LLM 生成摘要
- 摘要被注入上下文,既保留关键信息,又大幅减少 Token 数量
- 在长时程运行的智能体(如多回合对话 Agent)中,这是 核心技术
3.4 智能体系统的上下文管理
从 HITL → SITL
- Prompt Engineering:本质是 Human-in-the-Loop(HITL),依赖人工手动收集信息、组织语言、测试效果
- Context Engineering(Agentic 形态):转向 System-in-the-Loop(SITL),在 LLM 接收提示前,系统自动完成上下文准备
核心自动化模块:
- RAG:自动收集信息
- Router(路由器):自动决定收集哪些信息
- Memory 模块:自动持久化 & 检索历史信息
这种自动化让 AI 系统具备“智能体化”特征——无需人类逐步微观管理上下文,也能自主进行多步骤推理。
因此,Context Engineering 的目标是构建一台 可靠、可重复的上下文组装机器,从“手工技艺”转向“系统工程”。
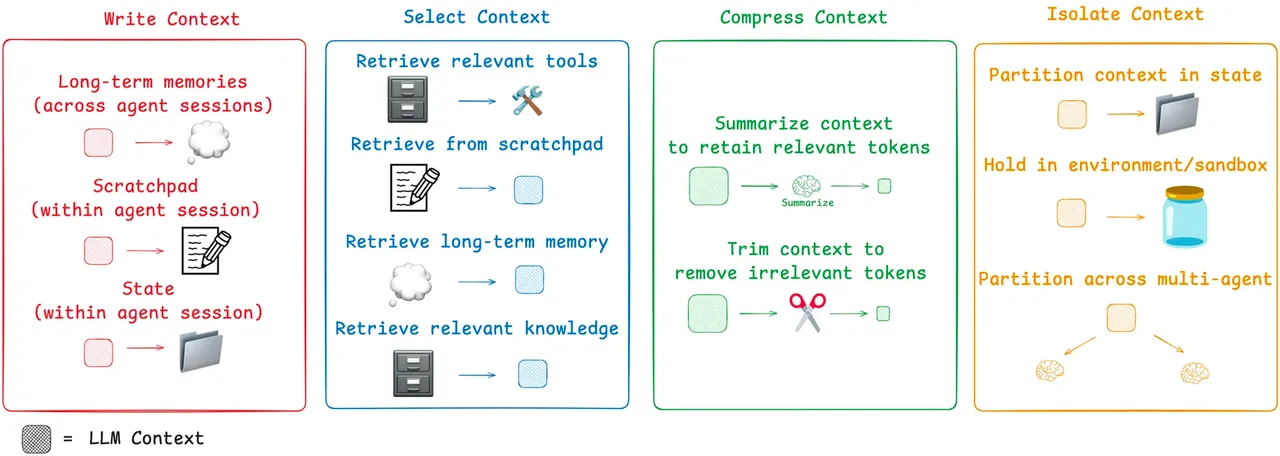
智能体上下文管理框架(LangChain 提出)
Write – 持久化上下文
- Scratchpads:临时、会话内记忆,用于记录中间推理步骤
- Memory:长期、持久化存储,保存关键事实、用户偏好、对话摘要,可跨会话调用
Select – 检索上下文
- 使用 RAG 技术,从记忆、知识库、工具库中动态选择相关上下文
- 甚至可对“工具描述”本身应用 RAG,避免为智能体提供过多无关工具选项
Compress – 优化上下文
- 利用摘要或修剪技术,管理长时程任务中不断增长的上下文
- 防止上下文窗口溢出及 Lost in the Middle 问题
Isolate – 分割上下文
- 多智能体系统:复杂问题拆分为子任务,每个子智能体独享专属、聚焦的上下文窗口
- 沙盒环境:在隔离环境中执行工具调用,仅将必要结果返回主上下文,避免大对象占据 Token
四、🚀 超越检索!智能体架构中的数据流与工作流编排
LLM 正在从被动地响应用户查询的“响应者”,演变为能够自主规划、决策并执行多步骤复杂任务的“执行者”——即我们所说的“智能体”(AI Agent)。
当一个智能体不再是简单地“输入-输出”,而是需要调用工具、访问数据库、与用户进行多轮交互时,其内部的数据是如何流动和管理的?如何进行技术选型?
4.1 工作流(Workflow) vs. 智能体(Agent)
在深入技术细节之前,建立一个清晰的概念框架至关重要。业界(如 Anthropic)倾向于对“智能体系统”进行两种架构上的区分。
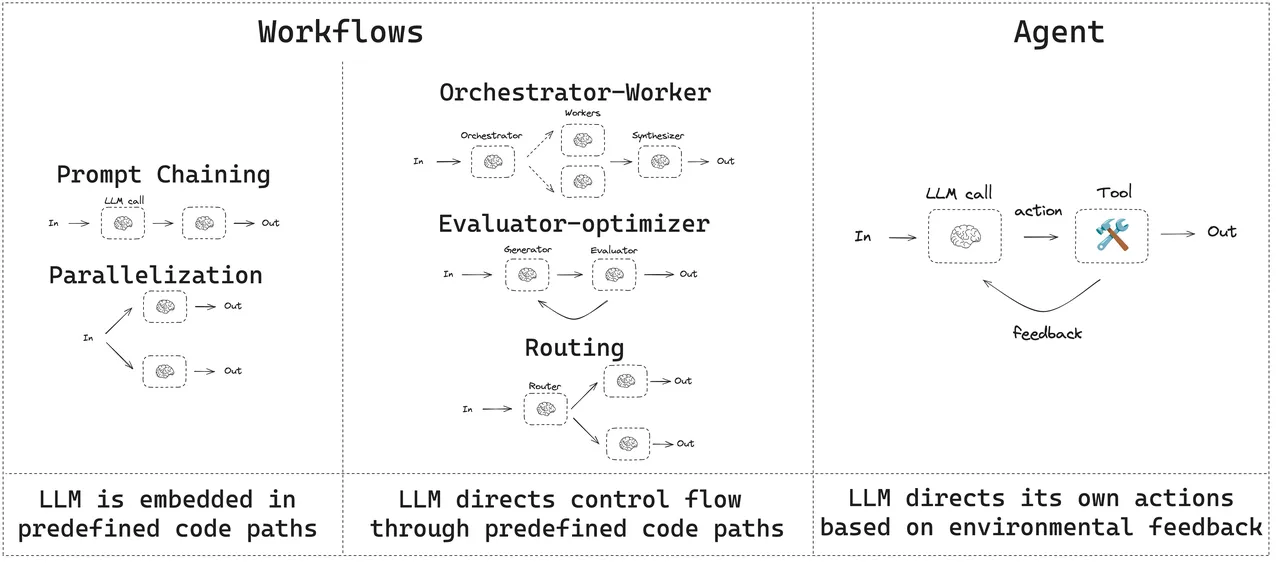
- 工作流(Workflows)
指的是LLM和工具通过预定义的代码路径进行编排的系统。在这种模式下,数据流动的路径是固定的、由开发者明确设计的,类似于上世纪流行的“专家系统”。例如:
第一步:分析用户邮件
第二步:根据分析结果在日历中查找空闲时段
第三步:起草会议邀请邮件
这种模式确定性高,易于调试和控制,非常适合有明确业务流程的场景(如风控需求高、数据敏感、安全等级要求)。
- 智能体(Agents)
指的是LLM动态地指导自己的流程和工具使用,自主控制如何完成任务的系统。在这种模式下,数据流动的路径不是预先固定的,而是由LLM在每一步根据当前情况和目标动态决定的。这种模式灵活性高,能处理开放式问题,但可控性和可预测性较低。
复杂的智能体通常是这两种模式的混合体,在宏观层面遵循一个预定义的工作流,但在某些节点内部,又赋予LLM一定的自主决策权。管理这一切的核心,我们称之为编排层(Orchestration Layer)。
4.2 核心架构:预定义数据流的实现
为了实现可靠、可控的数据流动,开发者们已经探索出几种成熟的架构模式。这些模式可以单独使用,也可以组合成更复杂的系统。
1. 链式工作流(Prompt Chaining)
- 数据流:输入 -> 模块A -> 输出A -> 模块B -> 输出B -> … -> 最终输出
- 工作原理:每个模块(LLM调用)只负责一个定义明确的子任务。
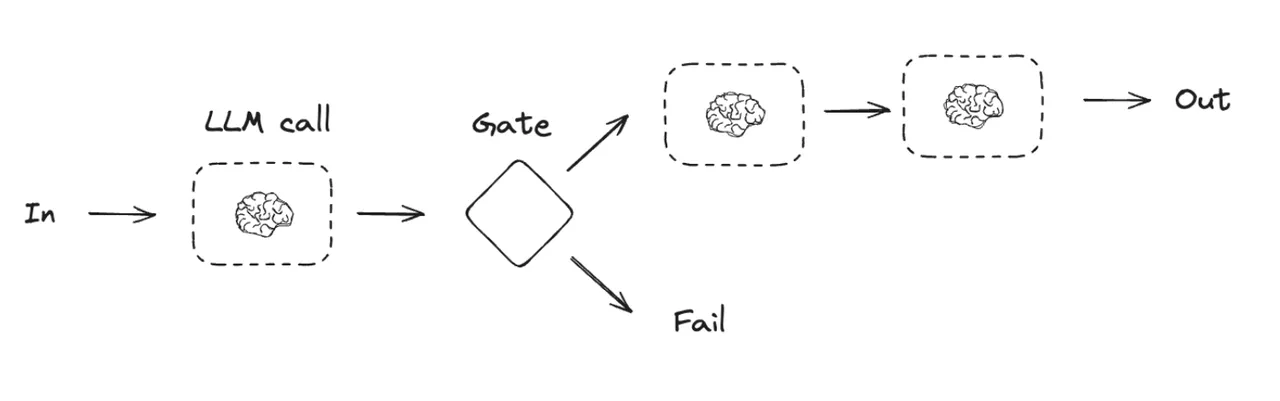
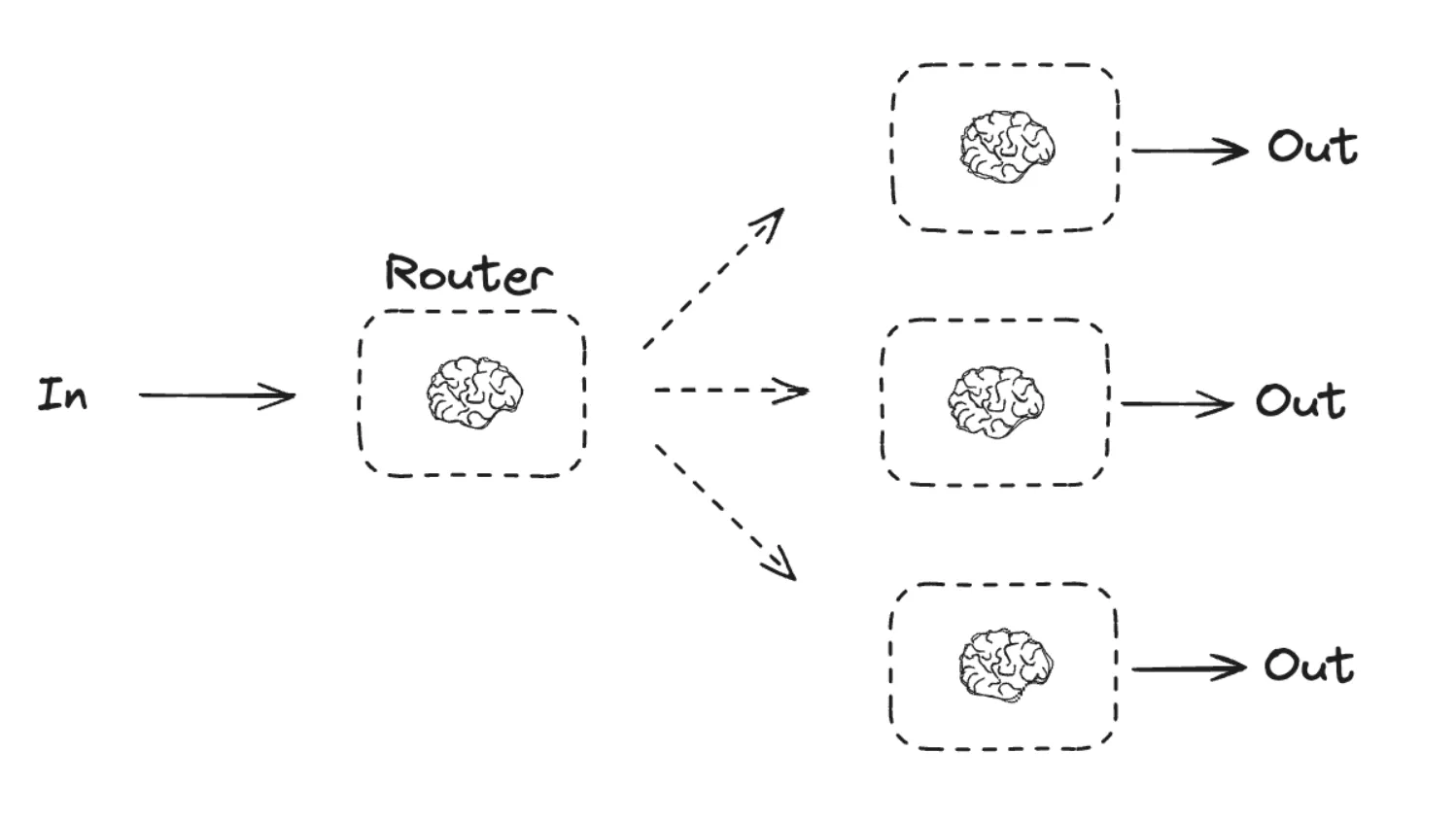
2. 路由工作流(Routing)
- 数据流:输入 -> 路由器选择 => -> 输出
- 工作原理:一个充当“路由器”的LLM调用,其唯一任务就是决策。它会分析输入数据,然后输出一个指令,告诉编排系统接下来应该调用哪个具体的业务模块。
- 实现方式:LangGraph 使用 Conditional Edges 来实现这种逻辑,即一个节点的输出决定了图的下一跳走向何方。
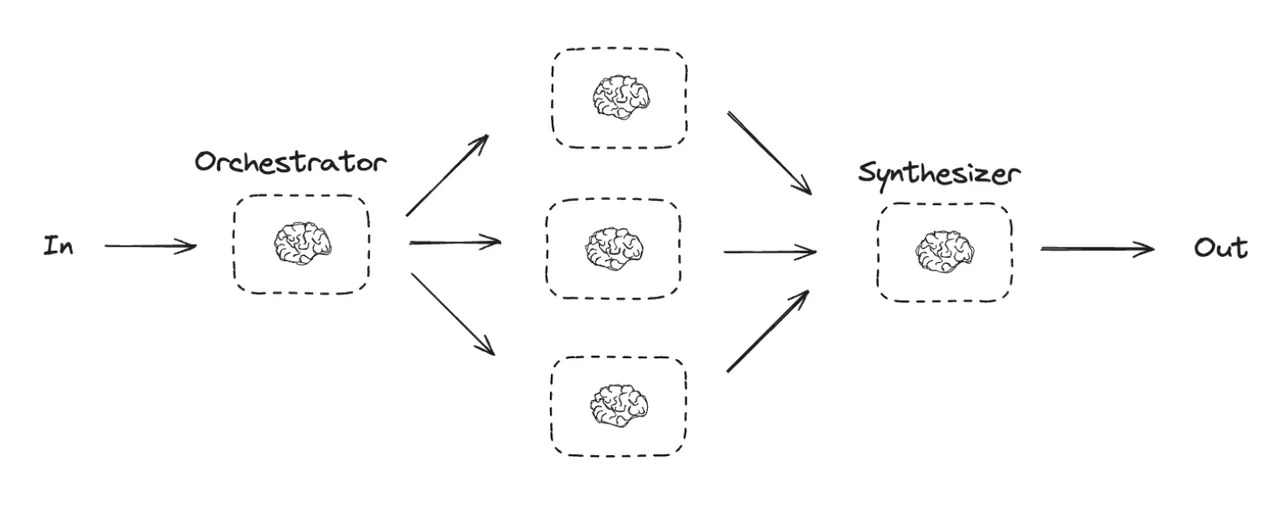
3. 编排器-工作者模式(Orchestrator-Workers)
- 对于极其复杂的任务,可以采用多智能体(Multi-agent)架构,也称为 Orchestrator-Workers 模式。一个中心 Orchestrator 智能体负责分解任务,并将子任务分配给多个专职的 Workers 智能体。
- 数据流:这是一个分层、协作的流动模式。总任务 -> Orchestrator => -> 结果汇总 -> 最终输出
- 工作原理:每个工作者智能体都有自己独立的上下文和专用工具,专注于解决特定领域的问题。
4.3 决策与数据选择机制
在上述架构中,智能体(或其模块)如何决定“需要什么数据”以及“下一步做什么”?这依赖于其内部的规划和推理能力。
ReAct框架
ReAct(Reasoning and Acting)是一个基础且强大的框架,它通过模拟人类的“Reasoning-Acting”模式,使LLM能够动态地决定数据需求。
(Anthropic早期的 MCP 客户端就基于这个架构)
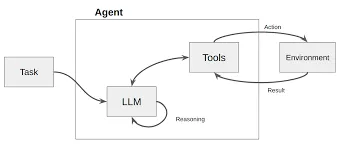
其核心是一个循环:
思考(Thought):LLM首先进行内部推理。它分析当前任务和已有信息,判断是否缺少完成任务所需的知识,并制定下一步的行动计划。
例如:“用户问我今天旧金山的天气,但我不知道。我需要调用天气查询工具。”行动(Action):LLM决定调用一个具体的工具,并生成调用该工具所需的参数。
例如:Action: search_weather(location="San Francisco")。观察(Observation):系统执行该行动(调用外部API),并将返回的结果作为“观察”数据提供给LLM。
例如:Observation: "旧金山今天晴,22摄氏度。"再次思考:LLM接收到新的观察数据,再次进入思考环节,判断任务是否完成,或是否需要进一步的行动。
例如:“我已经获得了天气信息,现在可以回答用户的问题了。”
在这个循环中,数据流是根据LLM的“思考”结果动态生成的。当LLM判断需要外部数据时,它会主动触发一个“行动”来获取数据,然后将获取到的“观察”数据整合进自己的上下文中,用于下一步的决策。
Planning和任务分解
对于更复杂的任务,智能体通常会先进行规划(Planning)。一个高阶的规划模块会将用户的宏大目标分解成一系列更小、更具体、可执行的子任务。
- 数据流向:规划模块的输出是一份“计划清单”(Planning List),这份清单定义了后续一系列模块的调用顺序和数据依赖关系。
(前一阵子流行的 Claude Code,刚更新的 Cursor v1.2,以及上个版本流行的 Gemini/GPT DeepResearch 就属于这个架构)
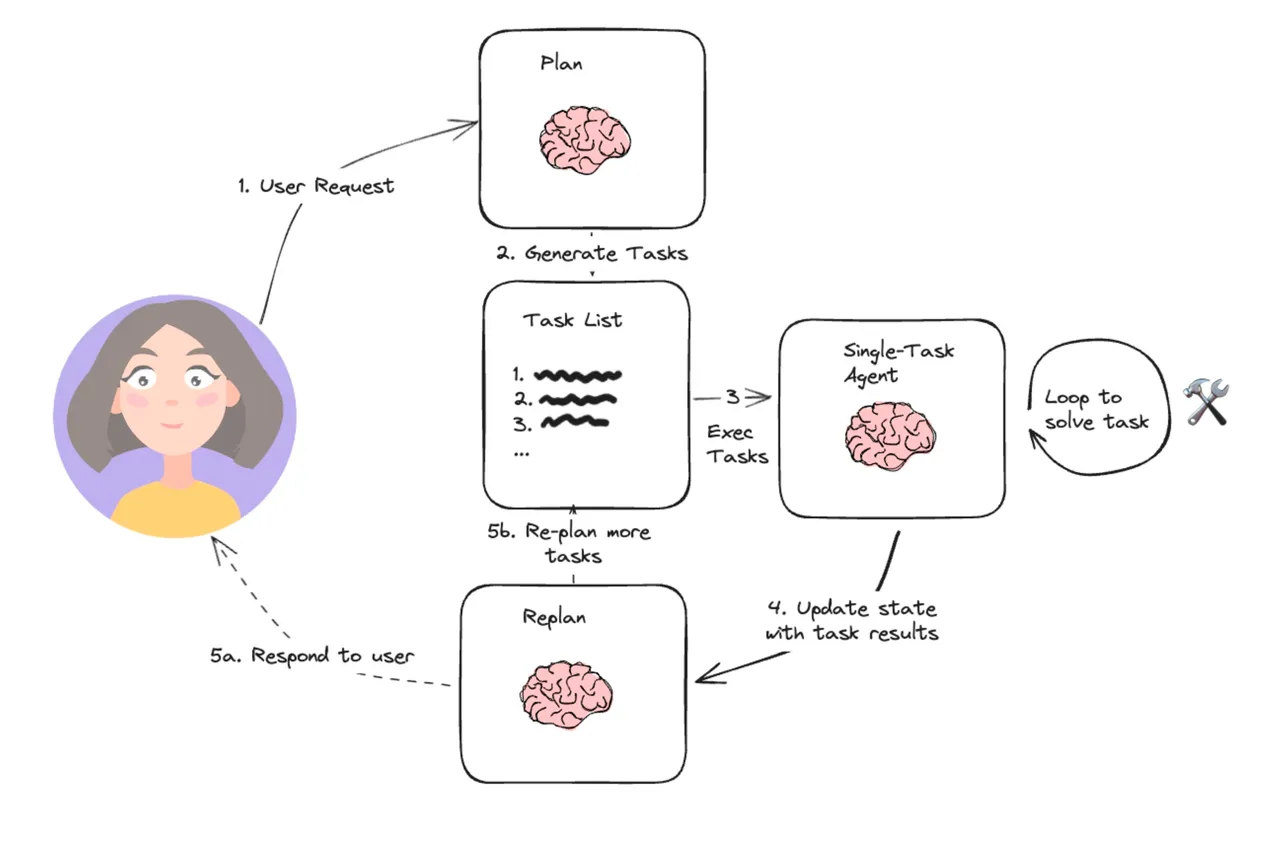
例如,对于“帮我策划一次巴黎三人五日游”的请求,规划模块可能会生成如下计划,并定义了每个步骤所需的数据输入和输出:
1.[获取用户预算和偏好] -> [搜索往返机票]
2.[机票信息] -> [根据旅行日期和预算搜索酒店]
3.[酒店信息] -> [规划每日行程]
4.[机票、酒店、行程信息] -> [生成最终行程单和预算报告]
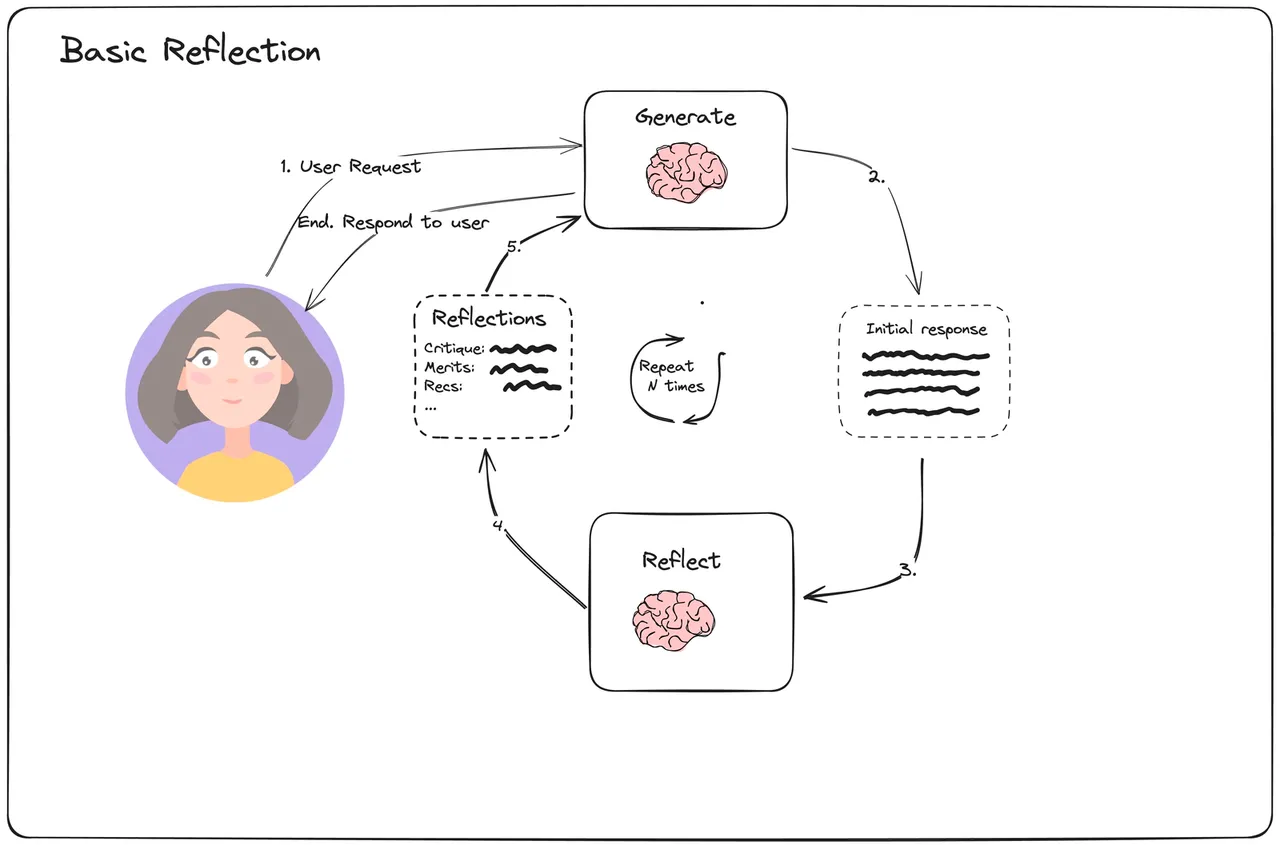
5.Reflection机制
先进的智能体架构还包含反思(Reflection)机制。智能体在执行完一个动作或完成一个子任务后,会评估其结果的质量和正确性。如果发现问题,它可以自我修正,重新规划路径。
(这是截止撰文时,各大主流 deep research 平台使用的核心技术方案)
- 数据流向:这是一个反馈循环。模块的输出不仅流向下一个任务模块,还会流向一个“评估器”模块。评估器的输出(如“成功”、“失败”、“信息不足”)会反过来影响规划模块,从而调整后续的数据流向。
4.4 框架与工具
上述的架构和机制并非凭空存在,而是通过具体的开发框架实现的。其中,LangGraph 作为 LangChain 的扩展,为构建具有显式数据流的智能体系统提供了强大的工具集。
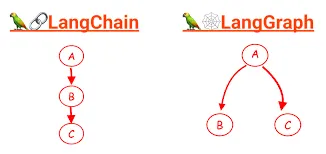
LangGraph:用图(Graph)定义工作流(Workflow)
LangGraph 的核心思想是将智能体应用构建成一个状态图(State Graph)。这个图由节点和边组成,清晰地定义了数据如何在不同模块间流动:
- 状态(State):这是整个图的核心,一个所有节点共享的中央数据对象。可以将其视为“数据总线”或共享内存。开发者需要预先定义 State 的结构,每个节点在执行时都可以读取和更新这个 State 对象。
- 节点(Nodes):代表工作流中的一个计算单元或一个步骤。每个节点通常是一个 Python 函数,它接收当前的 State 作为输入,执行特定任务(如调用 LLM、执行工具、处理数据),然后返回对 State 的更新。
- 边(Edges):连接节点,定义了工作流的路径,即数据在 State 更新后应该流向哪个节点。
- 简单边(Simple Edges):定义固定、无条件的流向,用于实现链式工作流。
- 条件边(Conditional Edges):用于实现路由逻辑。根据函数输出决定下一个节点,实现流程分支。
- 检查点(Checkpointer):提供持久化机制,可在每一步执行后自动保存 State 的状态。适用于长期记忆、可中断和恢复或 Human-in-the-Loop 的复杂业务流程。
复杂业务流程的 AI 智能体,其核心挑战已从单纯优化信息检索(如 RAG)或提示词,转向了对内部工作流和数据流的精心设计与编排。
五、Context Engineering 的未来
- Graph RAG 的兴起:标准基于向量的 RAG 在处理高度互联的数据时存在局限。利用知识图谱的图 RAG 不仅能检索离散信息块,还能检索它们之间的显式关系,实现多跳推理并提供更准确的上下文回答。
- 智能体自主性的增强:Self-RAG 和 Agentic RAG 等更自主系统成为趋势,LLM 承担更多自身上下文管理责任,模糊 Context Engineering 系统与 LLM 的界限。
- 超越固定上下文窗口:针对 Lost in the Middle 问题的研究,包括改进位置编码和训练技术,可能从根本上改变 Context Engineering 面临的约束。
- 终极目标:Context Engineering 是一座桥梁,补偿 LLM “don’t read minds—they read tokens”的现实。长期目标是创造具有更强内部世界模型的 AI,减少对庞大外部上下文支架的依赖。其演进是衡量这一目标进展的关键指标。
Citation
- Microsoft Press Store
- Google Cloud - Prompt Engineering for AI Guide
- arXiv:2402.07927v2
- AWS - What is Prompt Engineering?
- arXiv:2506.05614v1
- LangChain Blog - The rise of “context engineering”
- LangChain Blog - Context Engineering
- PMC - Unleashing the potential of prompt engineering
- Prompting Guide - Retrieval Augmented Generation (RAG)
- NVIDIA Blog - What Is Retrieval-Augmented Generation aka RAG
- arXiv:2311.09198v2 - Never Lost in the Middle
- Databricks - Mastering Chunking Strategies for RAG
- Python LangChain - Contextual Compression
- Milvus - Choosing Vector Databases
- Sentence Transformers - Retrieve & Re-Rank
- Stanford CS - Lost in the Middle
- Anthropic - Building Effective AI Agents
- IBM - LLM Orchestration
- LangGraph Agent Architectures
- IBM - ReAct Agent
- Prompt Engineering Guide - LLM Agents