
专业综合实训
专业综合实训课题
写在前面
1.第一步你需要将数据集文件下载,并移植到你的数据库里。
2.推荐使用自己的电脑进行实训。如果用机房电脑记得每次将自己的数据库导出为sql文件并保存以便下次使用。
3.以下每个题目其实都可以从课本上项目更改而来,比如将最热房源改为最热电影等
统一技术要求
- 后端:Python + Flask
- 数据库:MySQL(建议字符集
utf8mb4) - 前端:HTML/CSS/JavaScript(模板引擎 Jinja2)也可使用其他框架
- 数据分析与可视化:ECharts,Matplotlib(可选),scikit-learn(加分项)
- 通用功能要求:每个题目必须包含 注册/登录、至少 1 张业务表的 CRUD、至少 5 个 接口(写清请求方式、路由、数据格式)
- 关于数据库的表设计以及接口设计,仅作为参考,不要求一致。
以下数据均由本人收集自阿里云天池的开源数据集,仅用于实训,不保证数据真实
数据库操作说明:
1. 可借助navicat将我们的xls文件或csv文件导入到mysql
2. 使用navicat添加数据库的方法参照学习通课程资料内的视频 -数据库导入方式
3. 以就业数据集为例,视频中使用到的查询命令为:查询命令可把我们的表格发给ai,让ai给你生成命令,注意数据库的字符集
1 | -- 创建数据库,强制指定utf8mb4字符集和对应排序规则 |
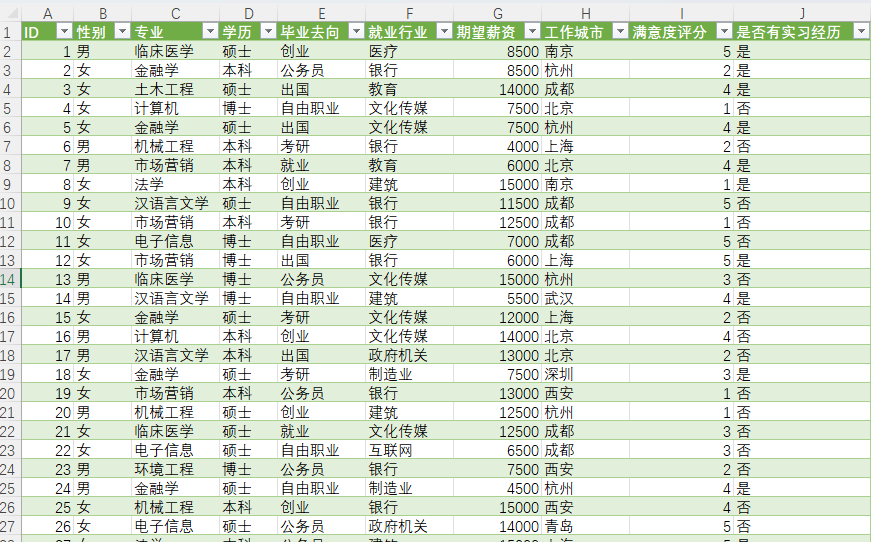
题目一:大学生就业去向分析与推荐平台(基于“大学生就业去向”数据集)
1. 项目简介
开发一个面向高校学生的就业信息与数据分析平台。学生可注册登录后浏览就业趋势、按专业/学历/城市筛选数据,收藏感兴趣的行业或城市,并生成个人就业画像。管理员可维护数据、发布公告。
2. 核心功能
- 用户:注册 / 登录 / 退出、修改资料、修改密码
- 数据:就业记录列表展示、条件筛选、详情查看
- 业务:收藏行业/城市、提交就业意向(可选)
- 管理员:用户管理、公告管理、数据维护(增删改)
- 数据分析:
- 专业 → 毕业去向分布
- 实习经历 vs 期望薪资 / 满意度
- 工作城市热度排行
-(可选)sklearn:预测“毕业去向”或“满意度区间”
3. 数据库表设计建议(MySQL)
3.1 user(用户表)
idBIGINT PK AIusernameVARCHAR(50) UNIQUE NOT NULLpassword_hashVARCHAR(255) NOT NULLroleENUM(‘user’,’admin’) DEFAULT ‘user’created_atDATETIME DEFAULT CURRENT_TIMESTAMP
3.2 employment_record(就业数据表)
idBIGINT PK AIgenderVARCHAR(10)majorVARCHAR(100)degreeVARCHAR(50)destinationVARCHAR(50)industryVARCHAR(100)expected_salaryDOUBLEcityVARCHAR(50)satisfaction_scoreDOUBLEhas_internshipTINYINT(1) DEFAULT 0
索引建议:major、city、destination
3.3 favorite(收藏表)
idBIGINT PK AIuser_idBIGINT NOT NULL(FK → user.id)fav_typeENUM(‘industry’,’city’,’record’) NOT NULLtarget_valueVARCHAR(255) NOT NULL(如“互联网/北京/记录ID”)created_atDATETIME DEFAULT CURRENT_TIMESTAMP
索引建议:(user_id, fav_type)、target_value
3.4 notice(公告表)
idBIGINT PK AItitleVARCHAR(100) NOT NULLcontentTEXT NOT NULLcreated_atDATETIME DEFAULT CURRENT_TIMESTAMPcreated_byBIGINT(admin user_id)
4. 接口设计(示例)
4.1 认证
- POST
/register(username, password) - POST
/login(username, password) - POST
/logout
4.2 就业数据 CRUD(管理员可写,普通用户只读)
- GET
/employment(page, page_size, major, city, degree, destination, has_internship) - GET
/employment/<id> - POST
/employment(新增记录,admin) - PUT
/employment/<id>(修改,admin) - DELETE
/employment/<id>(删除,admin)
4.3 收藏
- POST
/favorites(fav_type, target_value) - GET
/favorites - DELETE
/favorites/<id>
4.4 数据分析
- GET
/employment/analysis/major_destination(返回饼图数据) - GET
/employment/analysis/city_top?n=10 - GET
/employment/analysis/internship_salary(对比柱状图)
-(可选)POST/employment/ml/predict_destination(输入个人信息 → 预测去向)
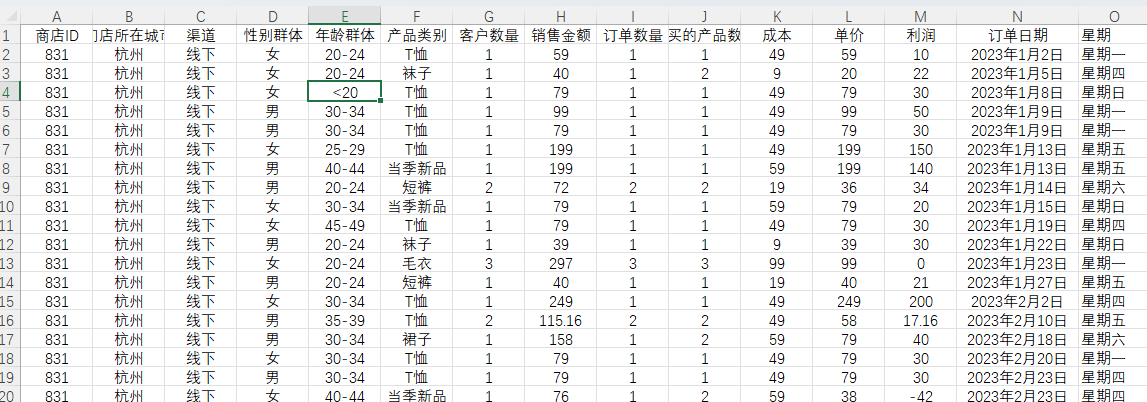
题目二:优衣库门店销售分析与商品管理系统(基于“优衣库销售数据”)
1. 项目简介
开发一个“零售销售数据管理与分析系统”,模拟优衣库门店经营数据。支持登录后查看门店销售、订单、利润等信息,并提供按城市/渠道/类别/日期的可视化分析。管理员可维护销售记录与商品类别。
2. 核心功能
- 用户:注册登录、个人中心
- 数据:销售记录 CRUD(管理员)、普通用户查询
- 业务:收藏门店/产品类别、下载报表(可选)
- 数据分析:
- 城市销售额 Top10
- 渠道(线上/线下)销售对比
- 类别利润率对比
- 日期趋势(按周/按日)
-(可选)sklearn:利润预测/销售额预测(回归)
3. 数据库表设计(MySQL)
3.1 user
同题目一
3.2 uniqlo_sales(销售事实表)
idBIGINT PK AIstore_idVARCHAR(50)cityVARCHAR(50)channelVARCHAR(50)gender_groupVARCHAR(50)age_groupVARCHAR(50)categoryVARCHAR(100)customer_countINTsales_amountDOUBLEorder_countINTproduct_countINTcostDOUBLEunit_priceDOUBLEprofitDOUBLEorder_dateDATEweekdayVARCHAR(20)
索引建议:order_date、city、category、channel
3.3 store(门店维表,可选)
store_idVARCHAR(50) PKcityVARCHAR(50)open_dateDATE NULLaddressVARCHAR(255) NULL
3.4 favorite
同题目一(fav_type=store/category)
4. 接口设计
4.1 销售记录查询/CRUD
- GET
/sales(page, city, channel, category, date_from, date_to) - GET
/sales/<id> - POST
/sales(admin) - PUT
/sales/<id>(admin) - DELETE
/sales/<id>(admin)
4.2 分析接口(给 ECharts)
- GET
/sales/analysis/city_top?n=10 - GET
/sales/analysis/channel_compare(线上 vs 线下) - GET
/sales/analysis/category_profit_rate - GET
/sales/analysis/timeseries?freq=day|week|month
-(可选)GET/sales/ml/regression_report(回归模型指标)
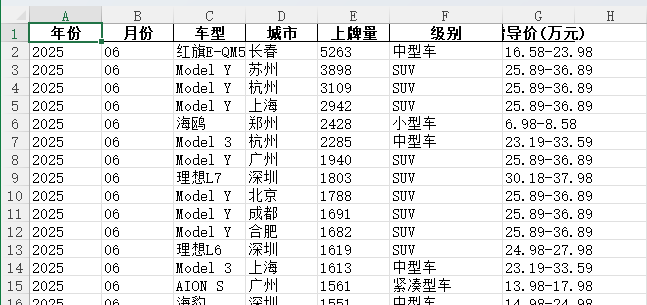
题目三:全国汽车上牌数据查询与趋势分析网站(基于“全国汽车上牌数据”)
1. 项目简介
构建一个汽车市场数据平台,用户登录后可查询不同城市、车型、级别在不同年月的上牌量,并展示趋势和对比分析。支持“关注车型/关注城市”。管理员可维护车型信息及上牌记录。
2. 核心功能
- 用户:注册登录、关注车型/城市
- 数据:上牌数据 CRUD(admin),用户查询与对比
- 数据分析:
- 城市上牌量排行
车型月度趋势折线图- 指导价分段与上牌量关系
-(可选)sklearn:车型聚类(价位+上牌量)
3. 数据库表设计(MySQL)
3.1 user
同题目一
3.2 car_plate(上牌事实表)
idBIGINT PK AIyearINTmonthINTmodelVARCHAR(100)cityVARCHAR(50)registrationsINTlevelVARCHAR(50)guide_price_wanDOUBLE
索引建议:(year, month)、city、model
3.3 favorite(关注表)
idBIGINT PK AIuser_idBIGINT NOT NULL(FK → user.id)fav_typeENUM(‘model’,’city’) NOT NULLtarget_valueVARCHAR(255) NOT NULLcreated_atDATETIME DEFAULT CURRENT_TIMESTAMP
4. 接口设计
4.1 查询与CRUD
- GET
/car/plates(year, month, city, model, level, price_min, price_max) - GET
/car/plates/<id> - POST
/car/plates(admin) - PUT
/car/plates/<id>(admin) - DELETE
/car/plates/<id>(admin)
4.2 分析接口
- GET
/car/analysis/city_top?n=10&year=2024 - GET
/car/analysis/model_timeseries?model=xxx&city=yyy - GET
/car/analysis/price_bucket
-(可选)GET/api/car/ml/kmeans_models?k=3
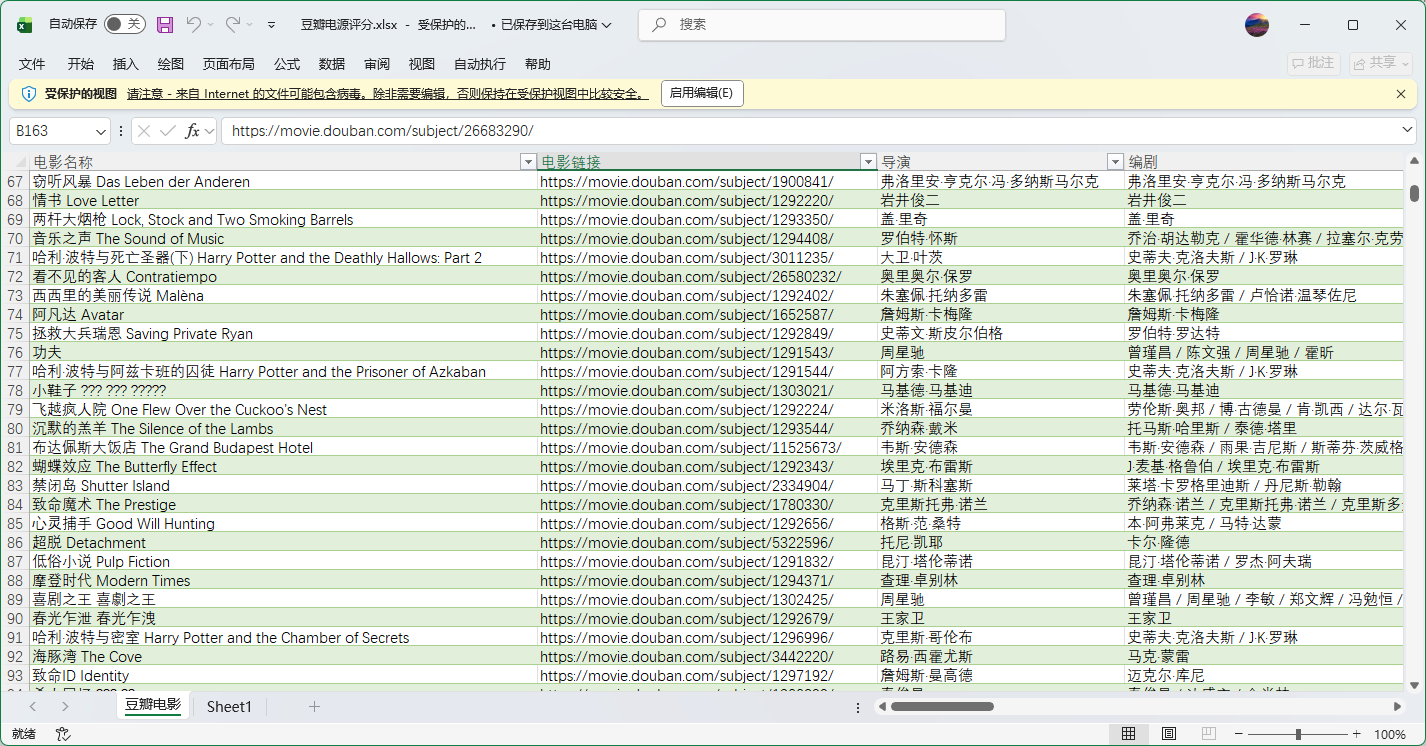
题目四:仿豆瓣影视评分网站(登录/收藏/评分分析)(基于“豆瓣影视评分”)
1. 项目简介
开发一个“仿豆瓣电影评分与收藏平台”。用户注册登录后可以浏览电影信息、搜索筛选、收藏电影、写短评(可选),并查看评分分布、热门类型等可视化分析。管理员可导入/维护电影数据。
说明:本项目使用提供的 xlsx 数据,仅作为课程数据练习,不做真实爬虫。
2. 核心功能
- 用户:注册登录、个人中心
- 电影:列表/详情/搜索(按类型、国家、评分区间、评价人数)
- 收藏:收藏/取消收藏、收藏列表
- 评论(可选):短评 CRUD
- 数据分析:
- 类型平均评分 + 评价人数
- 评分 TopN(带最小评价人数门槛)
- 星级比例(五星到一星)堆叠柱状图
-(可选)sklearn:电影聚类(评分+星级比例+人数)
3. 数据库表设计(MySQL)
3.1 user
同题目一
3.2 movie(电影表)
idBIGINT PK AImovie_nameVARCHAR(255)movie_urlVARCHAR(500)directorVARCHAR(255)writerVARCHAR(255)actorsTEXTgenreVARCHAR(255)countryVARCHAR(255)languageVARCHAR(100)release_dateVARCHAR(50)duration_minVARCHAR(50)aliasTEXTimdbVARCHAR(50)douban_scoreDOUBLErating_countINTstar5_pctDOUBLEstar4_pctDOUBLEstar3_pctDOUBLEstar2_pctDOUBLEstar1_pctDOUBLEsummaryTEXT
索引建议:douban_score、rating_count、genre
3.3 movie_favorite(电影收藏表)
idBIGINT PK AIuser_idBIGINT NOT NULL(FK → user.id)movie_idBIGINT NOT NULL(FK → movie.id)created_atDATETIME DEFAULT CURRENT_TIMESTAMP- UNIQUE KEY
uk_user_movie(user_id,movie_id)
3.4 review(短评表,可选)
idBIGINT PK AIuser_idBIGINT NOT NULLmovie_idBIGINT NOT NULLcontentTEXT NOT NULLcreated_atDATETIME DEFAULT CURRENT_TIMESTAMP
4. 接口设计
4.1 电影查询
- GET
/movies(page, keyword, genre, country, score_min, score_max, min_count) - GET
/movies/<id>
4.2 收藏
- POST
/movies/<id>/favorite - DELETE
/movies/<id>/favorite - GET
/me/favorites
4.3 分析接口
- GET
/movies/analysis/genre_score - GET
/movies/analysis/top_score?n=20&min_count=5000 - GET
/movies/analysis/star_stack?movie_id=<id>
-(可选)GET/movies/ml/kmeans?k=4